


「GA4のレポートでサンプリングが適用され正確な数値が見えない...」
「探索レポートで使える過去データが14ヶ月に限られてる....」
「複数の広告配信データとGA4を組み合わせて分析したいけど、手作業では時間がかかり過ぎる...」
GA4を使った分析でこんな課題に直面したことはありませんか?
実は、これらの課題をまとめて解決する方法があります。それが「GA4とBigQueryの連携」です。
BigQueryは、Googleが提供するクラウド型のデータウェアハウスサービスです。GA4と連携することで、サンプリングされていない生データの分析、無期限のデータ保存、さらには外部データとの高度な統合分析まで可能になります。
とはいえ、BigQuery連携と聞くと、こんな疑問をお持ちの方も多いはず。
「設定が難しそう」
「具体的に何ができるようになるの?」
本記事では、非エンジニアのマーケターでもわかりやすく、GA4とBigQueryの連携方法から実際の活用例、費用や注意点まで解説します。
なお、BigQueryの基本的な仕組みや特徴については以下で詳しく解説しています。「そもそもBigQueryって何?」という方は、まずはこちらをご覧いただくと、本記事の内容がより理解しやすくなります。
参考:非エンジニア向けの「BigQuery」入門|マーケ分析と業務効率化の第一歩


目次
なぜGA4×BigQuery連携を検討すべきか?
GA4の画面でも分析ができているのに、なぜBigQueryと連携する必要があるの?そう思われる方も多いでしょう。しかし、GA4単体での分析には制約があります。
GA4単体での3つの限界
GA4単体での分析で直面する制約を紹介します。それぞれ確認していきましょう。
1. サンプリング、しきい値の影響
GA4では「サンプリング」「しきい値」という仕組みがあります。
これらはGA4がデータを効率的に処理し、プライバシーを保護するための重要な機能ですが、正確な数値分析をしたい場合には課題となることがあります。
| サンプリング | GA4が大量のデータを効率的に処理するために一部のデータを選んで分析に利用する方法です。GA4ではイベント数やセッション数が非常に多い場合にサンプリングが適用されます。 これによりシステム負荷を軽減し素早くレポートを提供することが可能になっています。 |
|---|---|
| しきい値 | GA4がユーザーのプライバシーを保護するために、特定の条件下でデータを隠したりぼかしたりする仕組みです。 GA4では、対象となるユーザーに関するデータ(例:年齢、性別、興味関心など)が含まれる場合に、しきい値が適用されます。 |
※サンプリングとしきい値の詳細については、以下の記事で詳しく解説していますので、ぜひご確認ください
参考:GA4のサンプリングとは?仕組みや適用の条件、確認方法まで分かりやすく解説
参考:GA4のしきい値とは?仕組みや適用の条件、確認方法まで分かりやすく解説
2. データ保持期間(14か月)の制約
GA4では、無料版で最大14ヶ月、有料版のGA4 360でも最大50ヶ月までしかデータを保持できません。前年同月比の分析はできても、3年前、5年前との長期比較は不可能です。
3. 分析の柔軟性の限界
GA4の標準レポートや探索レポートは非常に優秀です。しかし「ユーザー軸で分析したい」「このデータとあのデータを組み合わせたい」という細かなニーズには対応できない場合があります。
例えば、以下のような分析は困難です。
- ユーザー単位の行動分析:初回訪問から購入までの全行動履歴を見たい
- 外部データと統合した分析:CRMデータとGA4データを突き合わせて分析したい
- 独自の計算指標をつかった分析:自社独自のLTV計算式で顧客価値を算出したい
これらの課題を解決する鍵が、BigQueryとGA4の連携にあります。
BigQuery連携でできること
上記の課題は、BigQueryとの連携によって解決できます。具体的に何が変わるのか、見ていきましょう。
1.サンプリング、しきい値なしの生データ分析
| GA4単体 | サンプリングやしきい値が適用され数値が表示される |
|---|---|
| BigQuery連携 | 収集されたイベントデータをそのまま分析可能 |
BigQueryと連携すると、GA4で収集されたユーザーのイベントデータ(無償版は1日100万イベントまで)が1件ごとに保存されます。Googleシグナル由来データや一部の広告データなどは除外されますが、保存されたデータはどんなに複雑な条件で絞り込んでも、サンプリング、しきい値が適用されることはありません。
2.データ保存期間の上限なし
| GA4単体 | 無料版:最大14ヶ月、360有料版:最大50カ月のデータ保持 |
|---|---|
| BigQuery連携 | 連携した日以降、何年分でもデータを保存可能 |
BigQuery連携により、データの保存期間を気にすることなく、長期的な分析基盤を構築できます。連携開始以降のイベントデータ(無償版は1日100万件まで)は自動的に蓄積され続けるため、数年単位での比較分析も可能です。なお、データ量に応じたストレージ料金が発生する点には注意が必要です。
3.GA4単体ではできない高度な分析
| GA4単体 | 決められたレポート形式での分析 |
|---|---|
| BigQuery連携 | SQL(データベースへ指示するための言語)を使った自由な分析が可能 |
BigQueryでは、SQL(データベースへ指示するための言語)を使って自由にデータを加工・分析ができます。
具体的には
- ユーザーの初回訪問から購入、その後のリピート購入まで時系列で可視化
- 自社のビジネスロジックに基づいた独自の指標も自由に作成可能。
- 初回購入から30日以内に2回目の購入をしたユーザーを優良顧客と定義
など、ビジネス固有の定義なども柔軟に実装できます。
4.外部データとの統合分析
| GA4単体 | GA4のデータのみで分析 |
|---|---|
| BigQuery連携 | BigQueryに連携したデータソースと統合可能 |
BigQueryの最大の魅力は、GA4のデータと他のデータソースを統合できる点にあります。
CRMシステムに蓄積された顧客情報があれば、顧客IDをキーにしてWeb上の行動とオフラインでの購買履歴を紐付けることができます。「Web上で特定のコンテンツを見た顧客は、店舗での購入単価が高い」といった、オンラインとオフラインをまたいだ分析も可能になるのです。
また、Google広告やFacebook広告などの広告データも統合すれば、実データを基にした費用対効果を一元的に管理できたり、在庫データと組み合わせれば、「WEB広告からどの商品がリピート率が高いか?」といった示唆の発見にもつながります。
このように、BigQuery連携は単なるデータ保存の手段ではなく、ビジネス全体のデータを統合的に分析するための基盤となります。
[GA4] BigQuery Export - アナリティクス ヘルプ
GA4とBigQueryの連携手順
ここからは実際の連携手順を解説します。権限の確認など事前準備がありますので順を追って進めていきましょう。
事前に必要な権限を確認
連携設定を始める前に、以下の権限があることを確認してください。
| GA4 | 編集者 または 管理者権限 |
|---|---|
| GoogleCloud(BigQuery) | BigQueryプロジェクト作成権限BigQuery管理者 権限 |
GA4とGoogleCloudは同じメールアドレスで権限が必要です。また、組織のGoogle Workspaceを使用している場合、IT部門に権限の確認や承認が必要な場合があります。事前に相談することをおすすめします。
ステップ1:Google Cloudプロジェクトの作成
BigQueryはGoogle Cloudのサービスなので、まずGoogle Cloudプロジェクトを作成します。
Google Cloud Consoleにアクセス
https://console.cloud.google.com/ にアクセスし、Googleアカウントでログインします。
新しいプロジェクトを作成
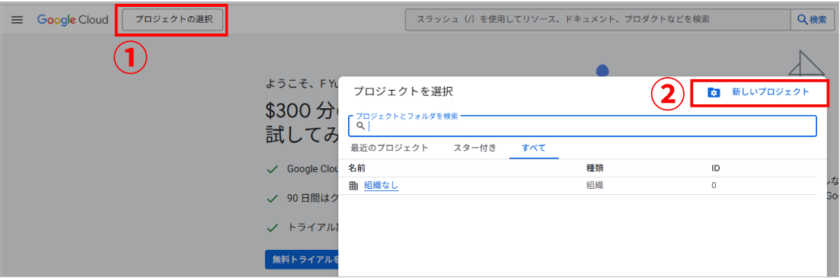
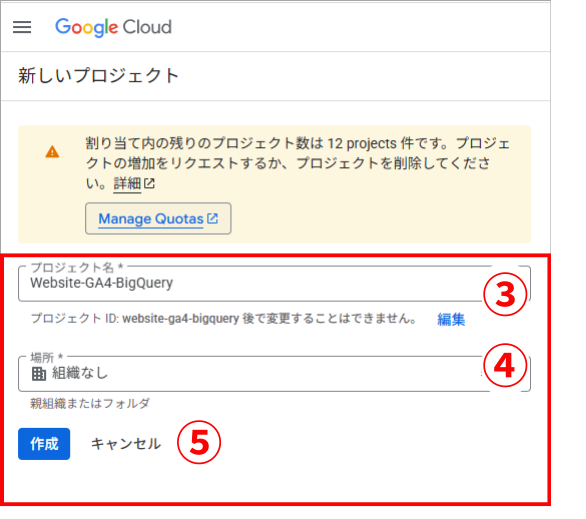
- 画面上部の「プロジェクトを選択」をクリック
- 「新しいプロジェクト」を選択
- プロジェクト名を入力(例「サイト名-GA4-BigQuery」 など、後から見て分かりやすい名前にしましょう)
- 組織を選択(個人の場合は「組織なし」でOK)
- 「作成」をクリック
ステップ2:BigQueryの有効化とデータセット作成
プロジェクトを作成したら、次はBigQueryを開いて、GA4のデータを保存する場所(データセット)を用意します。この作業はGA4から送られてくるデータの「受け皿」を作るイメージです。
BigQueryを開く
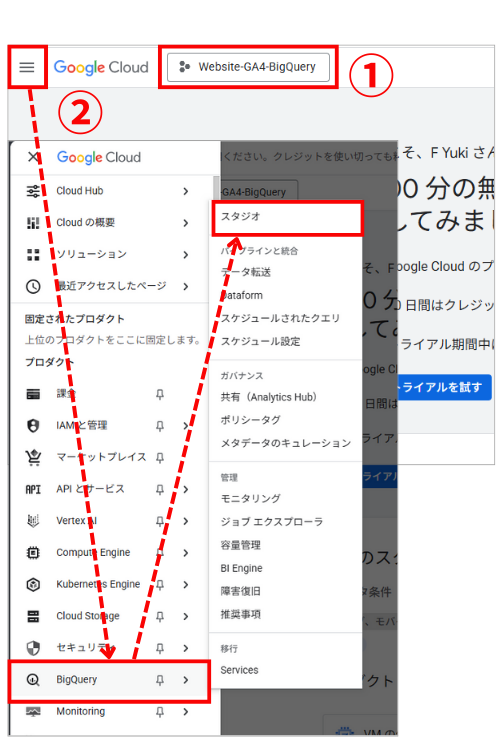
- Google Cloud Consoleで作成したプロジェクトを選択
- 左メニューから「BigQuery」→「スタジオ」を選択
BigQueryデータセットの作成
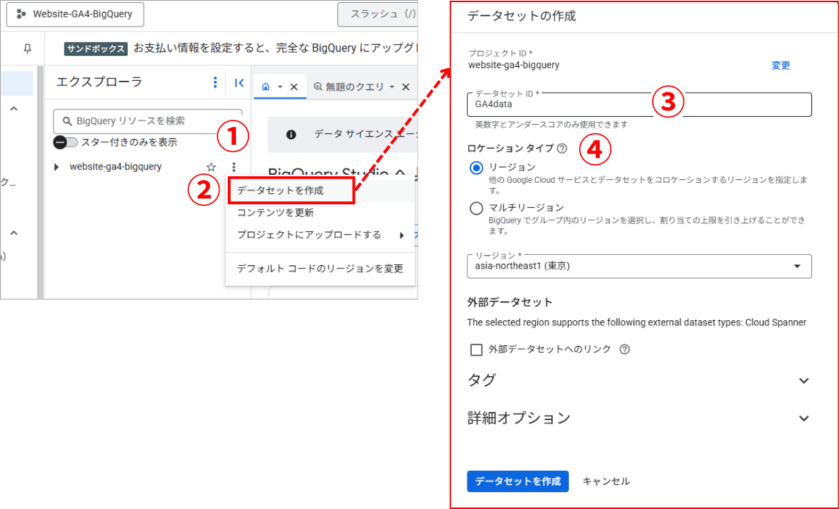
- プロジェクト名の横にある「⋮」メニューをクリック
- 「データセットを作成」を選択
- データセット名を入力
- データのロケーションを選択※注意!後述の注意点を参照
ステップ3:データロケーションの選択
データロケーションとはデータの保管所在地を表します。何か保管データに問題が起こった際に保管場所の地域の法律に基づき処理されたり、異なるロケーションに存在するデータは統合して分析ができません。一度設定すると変更できませんので慎重に選択しましょう。

日本企業におすすめのロケーション
asia-northeast1(東京)
- メリット: 日本国内にデータを保管、アクセス速度も高速
- デメリット: 他のデータが違うロケーションにある場合、統合分析不可
既存のBigQueryデータがある場合は、既存データと同じロケーションを選択、初めてBigQueryを使う場合は、asia-northeast1(東京)がおすすめです。
ステップ4:GA4からBigQueryエクスポートの設定
次はGA4の管理画面から、作成したBigQueryプロジェクトへの接続を設定していきます。
GA4管理画面での設定
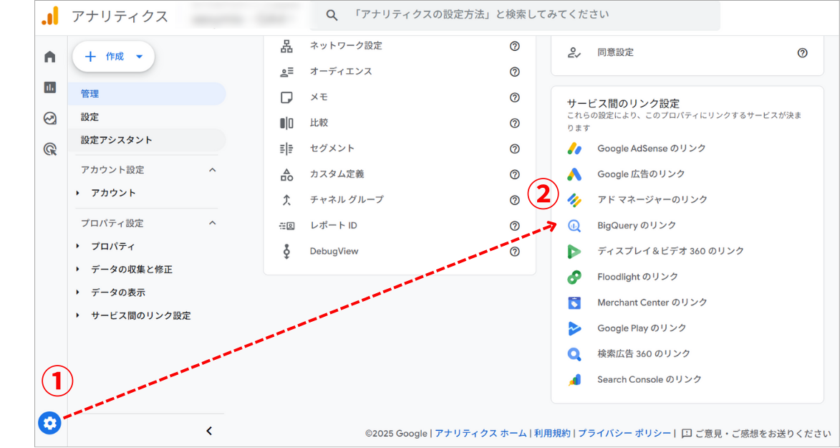
- 左下の「管理」(歯車アイコン)をクリック
- プロパティ列の「BigQueryのリンク」を選択
BigQueryプロジェクトの選択
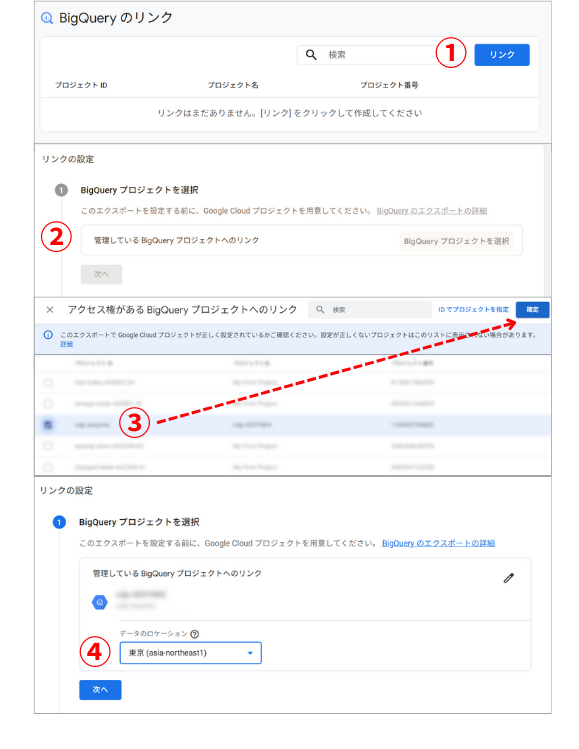
- 「リンク」をクリック
- 「BigQueryプロジェクトを選択」
- 先ほど作成したプロジェクトを選択、確定
- データの場所では、先ほど決めたロケーション(東京)を選択
エクスポート設定の選択
エクスポート方法は「日次エクスポート」と「ストリーミングエクスポート」の2つから選べます。
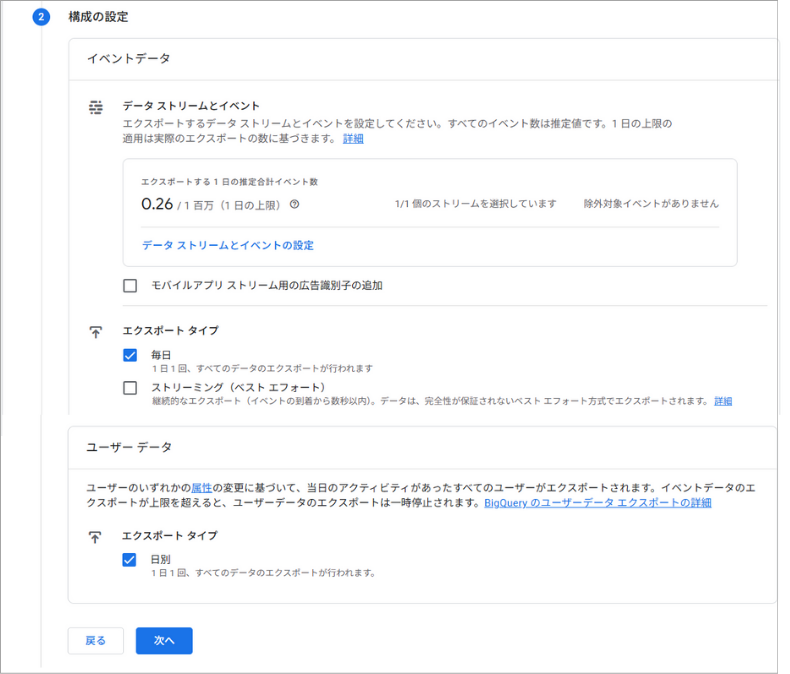
毎日エクスポート
- 毎日過去1日分のデータをエクスポート
- 無料(BigQueryの利用料金のみ)
ストリーミングエクスポート
- リアルタイムでデータをエクスポート
- BigQueryストリーミング料金が発生
初めての方には「日次エクスポート」をおすすめします。毎日深夜に前日分のデータが自動的に転送される仕組みで、追加料金もかかりません。リアルタイム分析が必要な場合以外は、日次エクスポートで十分活用が可能です。
設定の完了
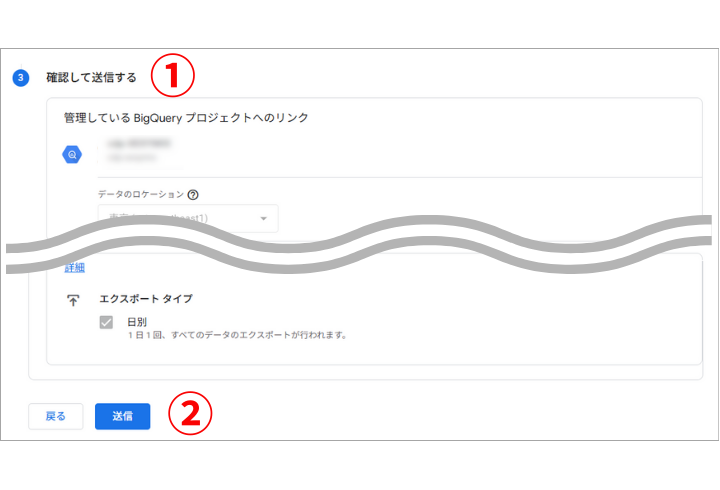
- 設定内容を確認
- 「送信」をクリック
ステップ5:設定完了の確認
BigQueryでのデータセット確認
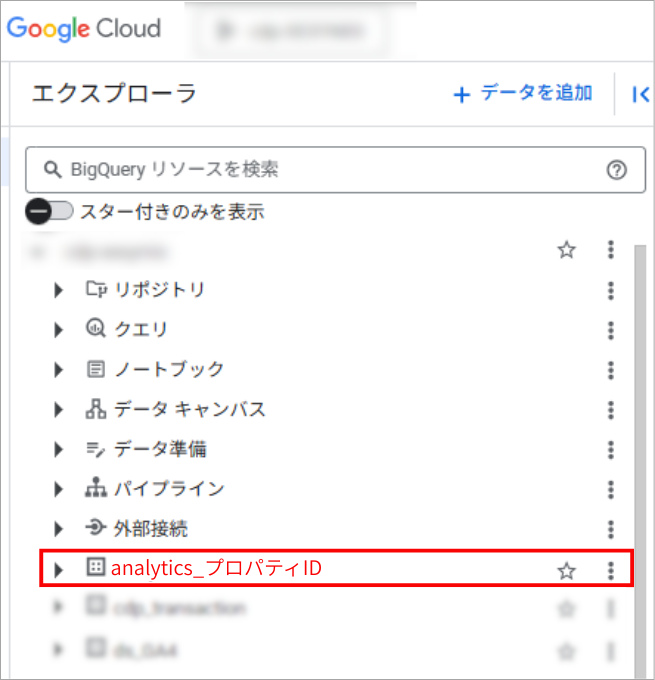
- BigQueryコンソールに戻る
- 左サイドバーで analytics_プロパティID というデータセットが作成されていることを確認
初回データの到着を待つ
日次エクスポートの場合は翌日の午前9時頃(日本時間)になります「events_YYYYMMDD」形式のテーブルが作成されるので確認しましょう。
- 日次エクスポート: 翌日の午前9時頃(日本時間)
- ストリーミング: 数分~数時間後
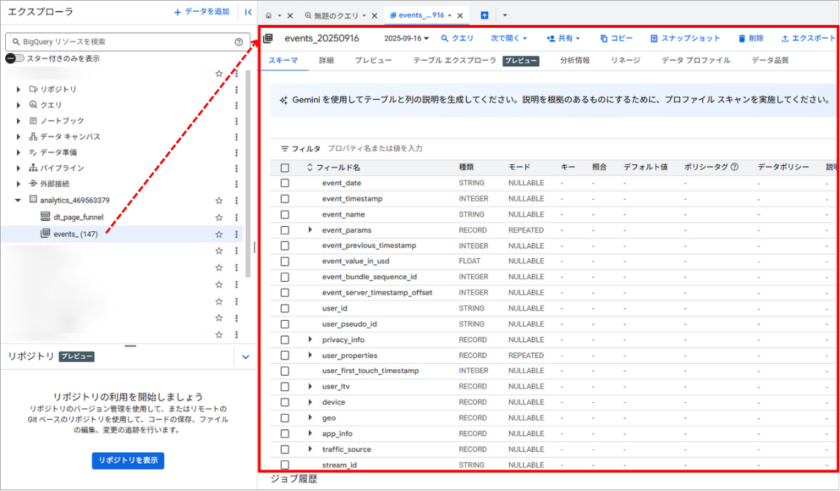
参考:[GA4] BigQuery Export のセットアップ
よくあるトラブルと対処法
設定は完了したはずなのに、エラーが表示される。データが反映されない。BigQuery連携の初期設定では、こうしたトラブルに遭遇することがあります。でも心配はいりません。下記2つをまずは確認しましょう。
権限がありません
原因: BigQueryの権限が不足
対処法: Google Cloudで「BigQuery管理者」権限を付与できているか再度確認しましょう
データセットが見つかりません
原因: データロケーションの不一致
対処法: GA4とBigQueryで同じロケーション(データの保管地域)が選択されているか確認しましょう。
GA4分析で使用できるSQL例
BigQueryの連携が完了したら、実際にSQLを使ってデータを分析してみましょう。
「SQLって難しそう...」と思われるかもしれませんが、心配ありません。
以下のクエリはコピー&ペーストで使えるよう準備しています。
まずは動かしてみることから始めましょう。
事前準備として以下のクエリを使用する前に、「BigQueryの参照するID」と「分析期間」は差し替えましょう
変更箇所
| your_project_id.analytics_123456789 | あなたのプロジェクトIDとGA4プロパティID |
|---|---|
| 20250901 と 20250930 | 分析したい期間 |
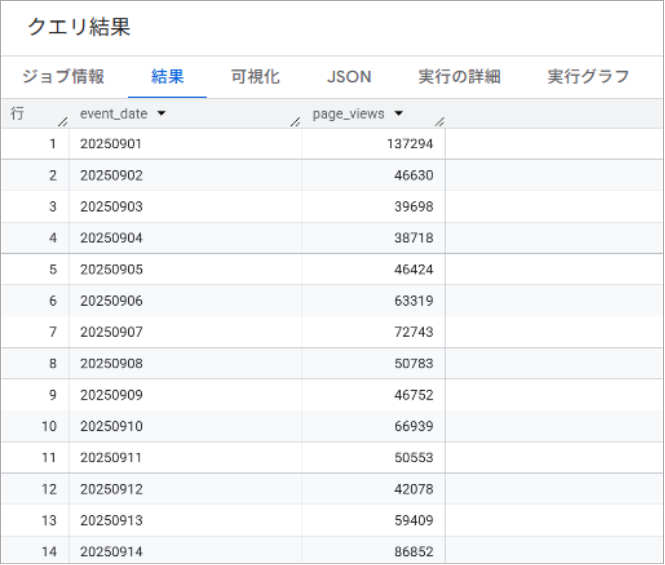
1. 日別ページビュー数の取得
最も基本的な分析として、日別のページビュー数を確認するクエリです。
SELECT
event_date,
COUNT(*) as page_views
FROM
`your_project_id.analytics_123456789.events_*`
WHERE
event_name = 'page_view'
AND _TABLE_SUFFIX BETWEEN '20250901' AND '20250930'
GROUP BY
event_date
ORDER BY
event_date結果の見方
各日付のページビュー数が一覧で表示されます。急激な増減がある日を特定して、その要因を調査する際に活用できます。
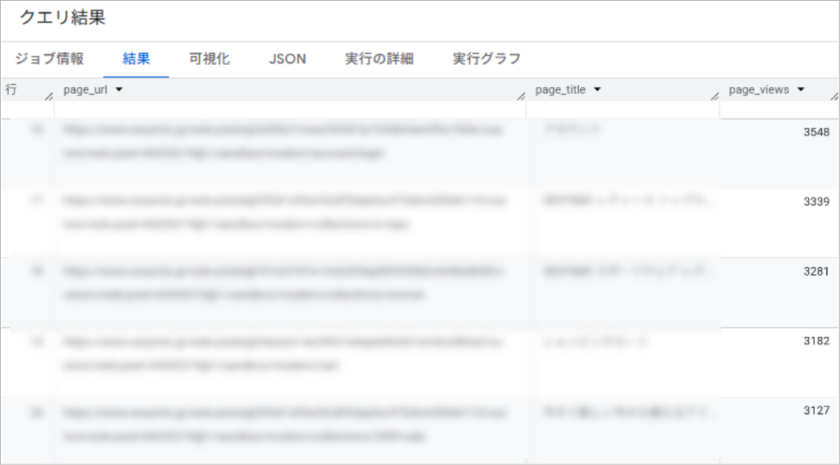
2. 人気ページランキング
どのページがよく見られているかを把握するためのクエリです。
SELECT
(SELECT value.string_value FROM UNNEST(event_params) WHERE key = 'page_location') as page_url,
(SELECT value.string_value FROM UNNEST(event_params) WHERE key = 'page_title') as page_title,
COUNT(*) as page_views
FROM
`your_project_id.analytics_123456789.events_*`
WHERE
event_name = 'page_view'
AND _TABLE_SUFFIX BETWEEN '20250901' AND '20250930'
GROUP BY
page_url, page_title
ORDER BY
page_views DESC
LIMIT 20備考:LIMIT 20:表示する件数(上位20位まで)
結果の見方
ページビュー数の多い順にページのURL、タイトル、ビュー数が表示されます。コンテンツ戦略の見直しや、人気コンテンツの傾向分析に活用できます。
3. 新規ユーザーの定着率分析
「新規ユーザーが何日後に再訪問するか」をユーザー単位で分析できます。
WITH user_first_visit AS (
SELECT
user_pseudo_id,
MIN(PARSE_DATE('%Y%m%d', event_date)) as first_visit_date
FROM
`your_project_id.analytics_123456789.events_*`
WHERE
event_name = 'session_start'
AND _TABLE_SUFFIX BETWEEN '20250901' AND '20250930'
GROUP BY
user_pseudo_id
),
user_return_visits AS (
SELECT
f.user_pseudo_id,
f.first_visit_date,
MIN(PARSE_DATE('%Y%m%d', e.event_date)) as first_return_date
FROM
user_first_visit f
LEFT JOIN
`your_project_id.analytics_123456789.events_*` e
ON
f.user_pseudo_id = e.user_pseudo_id
AND e.event_name = 'session_start'
AND PARSE_DATE('%Y%m%d', e.event_date) > f.first_visit_date
WHERE
e._TABLE_SUFFIX BETWEEN '20250901' AND '20250930'
GROUP BY
f.user_pseudo_id, f.first_visit_date
)
SELECT
DATE_DIFF(first_return_date, first_visit_date, DAY) as days_to_return,
COUNT(*) as user_count,
ROUND(COUNT(*) * 100.0 / SUM(COUNT(*)) OVER(), 2) as percentage
FROM
user_return_visits
WHERE
first_return_date IS NOT NULL
AND DATE_DIFF(first_return_date, first_visit_date, DAY) <= 30
GROUP BY
days_to_return
ORDER BY
days_to_return活用例
「新規ユーザーの37%は1日以内に再訪問する」「〇日後の再訪問率が最も高い」など、リターゲティング広告の配信タイミング設計に活用できます。
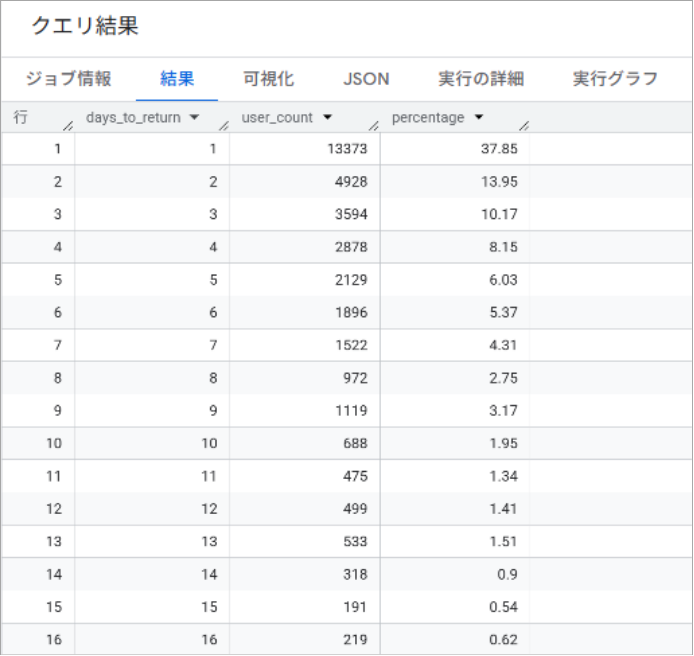
| カラム名 | 内容 |
|---|---|
| days_to_return | ユーザーがサイトに初めて訪問した日(初回訪問日)から、その次に訪問した日(初回再訪問日)までの経過日数を表します。 |
| user_count | days_to_returnで示された日数で再訪問したユニークユーザーの総数を表します。 |
| percentage | 各days_to_returnのユーザー数が、分析対象期間中(このSQLでは初回訪問から30日以内)に再訪した全ユーザー数に占める割合をパーセンテージで表します。 |
4. 流入元別ユーザー行動の深掘り分析
流入元(参照元)別に、そのセッション内での詳細な行動パターンを分析できます。
WITH
session_attribution AS (
SELECT
user_pseudo_id,
(SELECT value.int_value FROM UNNEST(event_params) WHERE key = 'ga_session_id') as session_id,
CONCAT(
COALESCE((SELECT value.string_value FROM UNNEST(event_params) WHERE key = 'source'), 'direct'),
' / ',
COALESCE((SELECT value.string_value FROM UNNEST(event_params) WHERE key = 'medium'), '(none)')
) AS source_medium
FROM
`your_project_id.analytics_123456789.events_*`
WHERE
event_name = 'session_start'
AND _TABLE_SUFFIX BETWEEN '20250901' AND '20250930' ),
session_events AS (
SELECT
user_pseudo_id,
(SELECT value.int_value FROM UNNEST(event_params) WHERE key = 'ga_session_id') as session_id,
event_name,
event_timestamp
FROM
`your_project_id.analytics_123456789.events_*`
WHERE
_TABLE_SUFFIX BETWEEN '20250901' AND '20250930'
AND event_name IN ('session_start', 'page_view')
),
session_summary AS (
SELECT
sa.source_medium,
se.user_pseudo_id,
se.session_id,
COUNT(CASE WHEN se.event_name = 'page_view' THEN 1 END) as page_views,
ROUND((MAX(se.event_timestamp) - MIN(se.event_timestamp)) / 1000000, 2) as session_duration_seconds
FROM
session_attribution sa
JOIN
session_events se ON sa.session_id = se.session_id AND sa.user_pseudo_id = se.user_pseudo_id
GROUP BY
sa.source_medium, se.user_pseudo_id, se.session_id
)
SELECT
source_medium,
COUNT(*) as sessions,
ROUND(AVG(page_views), 2) as avg_pages_per_session,
ROUND(AVG(session_duration_seconds), 2) as avg_session_duration,
ROUND(
SAFE_DIVIDE(
COUNTIF(session_duration_seconds > 10 OR page_views > 1),
COUNT(*)
) * 100, 2
) as engagement_rate_percent,
ROUND(
SAFE_DIVIDE(
COUNTIF(session_duration_seconds <= 10 AND page_views <= 1),
COUNT(*)
) * 100, 2
) as bounce_rate_percent
FROM
session_summary
WHERE
source_medium != ' / '
GROUP BY
source_medium
HAVING
sessions >= 10
ORDER BY
sessions DESC;
活用例
「Google検索からの流入は滞在時間が長いが、SNSからの流入はページビューが多い」など、流入元の特徴に応じた流入戦略の立案に活用できます。
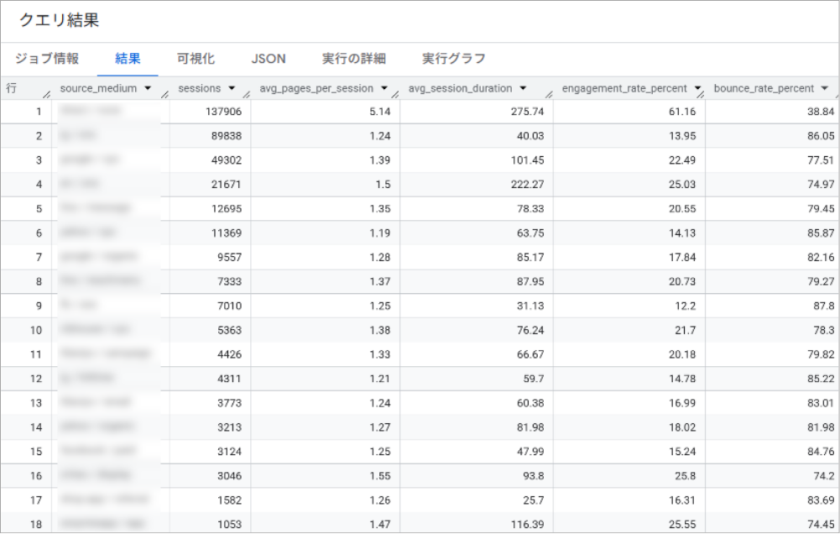
| カラム名 | 内容 |
|---|---|
| source_medium | ユーザーがどの経路でサイトに流入してきたかを示すsession_startが発生した際の参照元 / メディア |
| sessions | source_mediumから流入したセッションの総数です。 |
| avg_pages_per_session | 「平均ページビュー数」。1セッションあたりにユーザーが平均で何ページ閲覧したかを示します。 |
| avg_session_duration | 「平均セッション継続時間」。1セッションあたりの平均滞在時間を秒単位で示します。 |
| engagement_rate_percent | 「エンゲージメント率」。全セッションのうち、「エンゲージメントのあったセッション」の割合をパーセンテージで示します。 |
| bounce_rate_percent | 「直帰率」。全セッションのうち、「エンゲージメントのなかったセッション」の割合をパーセンテージで示します。 |
5. 初回購入チャネル別のリピート率分析
下記のクエリはpurchaseイベントを使用しています。
WITH PurchaseNumbering AS (
SELECT
user_pseudo_id,
event_timestamp,
CONCAT(
COALESCE(traffic_source.source, 'direct'),
' / ',
COALESCE(traffic_source.medium, '(none)')
) AS source_medium,
ROW_NUMBER() OVER(PARTITION BY user_pseudo_id ORDER BY event_timestamp) AS purchase_number
FROM
`your_project_id.analytics_123456789.events_*`
WHERE
event_name = 'purchase'
AND _TABLE_SUFFIX BETWEEN '20250401' AND '20250930'
),
UserFirstPurchaseCohort AS (
SELECT
user_pseudo_id,
MAX(CASE WHEN purchase_number = 1 THEN source_medium END) AS first_purchase_source_medium,
MAX(purchase_number) AS total_purchase_count
FROM
PurchaseNumbering
GROUP BY
user_pseudo_id
)
SELECT
first_purchase_source_medium AS initial_source_medium,
COUNT(user_pseudo_id) AS f1_total_users,
COUNTIF(total_purchase_count >= 2) AS f2_repeat_users,
COUNTIF(total_purchase_count >= 3) AS f3_repeat_users,
COUNTIF(total_purchase_count >= 4) AS f4_plus_repeat_users,
ROUND(SAFE_DIVIDE(COUNTIF(total_purchase_count >= 2), COUNT(user_pseudo_id)) * 100, 2) AS f2_conversion_rate_percent,
ROUND(SAFE_DIVIDE(COUNTIF(total_purchase_count >= 3), COUNT(user_pseudo_id)) * 100, 2) AS f3_conversion_rate_percent
FROM
UserFirstPurchaseCohort
WHERE
first_purchase_source_medium IS NOT NULL AND first_purchase_source_medium != ' / '
GROUP BY
initial_source_medium
ORDER BY
f1_total_users DESC;活用例
「Google検索から初回購入した顧客はF2転換率が約15%と高いが、SNS広告経由の顧客はF2転換率が8%に留まる」など、初回購入チャネル別のリピート特性を把握し、LTV(顧客生涯価値)の高いチャネルへの投資配分の最適化や、チャネル別のリテンション施策の立案に活用できます。
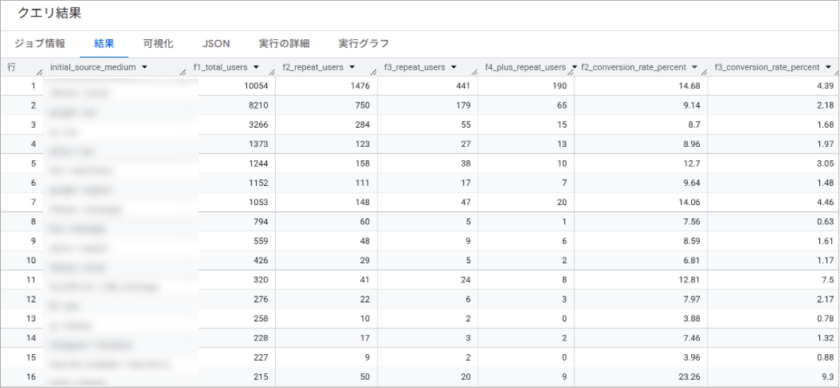
| カラム名 | 内容 |
|---|---|
| initial_source_medium | 初回購入時の流入経路(参照元/メディア)。ユーザーが最初に購入した際のトラフィックソース。 |
| f1_total_users | 初回購入者の総数。該当する流入経路から初めて購入したユーザーの合計数です。 |
| f2_repeat_users | 2回以上購入したユーザー数(F2転換者)。初回購入後、再度購入したリピーターの人数。 |
| f3_repeat_users | 3回以上購入したユーザー数(F3転換者)。3回目の購入まで至った優良リピーターの人数。 |
| f4_plus_repeat_users | 4回以上購入したユーザー数(F4+転換者)。4回以上購入したロイヤルカスタマーの人数。 |
| f2_conversion_rate_percent | f2転換率(%)初回購入者のうち2回目の購入に至った割合をパーセンテージで表示。 |
| f3_conversion_rate_percent | F3転換率(%)初回購入者のうち3回目の購入に至った割合をパーセンテージで表示。 |
※集計データに関する注意事項
本クエリは、GA4がCookieを基に自動付与するuser_pseudo_id(仮ユーザーID)を使用してユーザーを識別しています。そのため、Cookieを削除した場合や、異なるデバイス・ブラウザから購入した場合、プライベートモードを使用した場合などは、同一ユーザーでも別ユーザーとしてカウントされてしまいます。
より正確なリピート率を把握するには、GA4のUser-ID機能を実装するか、会員IDなどのCRMデータとBigQuery上で結合することをおすすめします。
まずは上記のクエリを実際に動かしてみて、BigQueryでの分析に慣れることから始めましょう。慣れてきたら、自社で実現したい分析レポートに応じてクエリをカスタマイズしていけば、GA4単体では見えなかった詳細な分析が可能になります。
より高度な分析を行いたい場合は、GA4のデータ構造を詳しく理解することが重要です。Googleの公式ヘルプでは、BigQueryにエクスポートされるデータの詳細な構造(スキーマ)が説明されているので、ぜひ参考にしてください。
GA4連携データの注意点
GA4連携データをと入り扱うにあたって注意点があります。
事前に知っておけば慌てることもないので、しっかり確認しておきましょう。
1.GA4レポートとBigQueryの数値は違う
GA4の管理画面とBigQueryで同じ期間・同じ指標を見ても、数値が一致しないことがあります。これは仕様の違いであり、不具合ではありません。
主な差異の原因
1. データ処理のタイミングの違い
GA4管理画面: リアルタイムで統合・集計処理
BigQuery: 生データを後から集計
2. サンプリング・しきい値の有無
GA4管理画面: サンプリング・しきい値あり(推定値)
BigQuery: サンプリング・しきい値なし(実値)
3. 日またぎセッションの扱い
GA4管理画面: 自動で日またぎを考慮
BigQuery: SQLで明示的に処理する必要
4.タイムゾーンの違い
GA4管理画面: プロパティで設定したタイムゾーン(日本ならJST)で表示
BigQuery: UTC(協定世界時)で保存・処理されます。この9時間のずれにより、特に日付の境界付近のイベントで数値の差異が生じます。BigQueryでJST基準の分析を行う場合は、タイムスタンプを変換する必要があります。
「どちらが正しいか」ではなく「用途に応じて使い分ける」ことが重要です。
精密な分析ならBigQueryの数値を使用、日々のモニタリングなら GA4管理画面を使用といった形で判断することがおすすめです。
参考:[GA4] アナリティクス レポートと BigQuery にエクスポートされたデータを比較する
2.無償版の制限(1日100万イベント)
GA4無償版をお使いの場合、BigQueryへのエクスポートは1日あたり100万イベントまでという制限があります。
月間100万PVを超える場合は、分析に必要なイベントだけをエクスポート対象に絞り込むことで対応できます。たとえば、ページビューや購入などの重要イベントは残しつつ、スクロールイベントのような分析頻度の低いものは除外する、といった工夫です。
上記でも解決できない場合、エクスポート制限の無いGA4 360(有料版)への移行を検討しましょう。
3.エクスポートされないデータ
BigQueryには、GA4で収集されるデータのすべてが送られるわけではありません。
エクスポートされないデータ一覧
| Googleシグナル由来のデータ | 年齢・性別などの推定属性情報、類似ユーザー情報、クロスデバイストラッキング情報 |
|---|---|
| Google広告の詳細データ | 広告コスト、インプレッション数などの広告と連携したデータ |
| 一部のGoogle Analytics Intelligence機能 | GA4上で自動生成されるインサイト、異常検知の結果などは計測データを基にGA4上で数値を出しているため、RAWデータでは出力されません |
足りないデータはBigQuery集約し統合
GA4連携では取得できないデータは、それぞれの管理画面やAPIから別途取得し、BigQuery上で統合することで解決できます。
例)
- Google広告データ:Google Ads APIやGoogle広告レポート
- 属性や購買データ:CRM上のデータで補完
GA4分析の可能性を広げる一歩に
BigQueryとの連携は、GA4の分析をより柔軟にための手段です。
ただし、BigQueryとの連携が必ずしも優れているわけではありません。日々のモニタリングにはGA4管理画面の方が早く確認できますし、BigQueryを使いこなすにはSQLの学習も必要です。
それでも連携をおすすめする理由は2つです。
1つ目は、データは連携した日からしか蓄積されないこと。後から「過去のデータが欲しい」と思っても手遅れです。
2つ目は、他のデータと統合したときに真価を発揮すること。CRMデータや広告データと組み合わせることで、今まで見えなかったデータからビジネス拡大のきっかけや改善点が見えてくるかもしれません。
今すぐ高度な分析ができなくても大丈夫です。まずはBigQueryと連携しデータを溜めながら、少しずつ分析スキルを身につけていきましょう!

Yuki Fujisawa
大学時代より今後生きていく為の業を手に入れたいという思いから成長産業であるネット広告に興味を持ち、2017年10月からアナグラムに参画。ただ目標の数字を達成するだけでなく、クライアントさんに安心して頼っていただける存在になれるよう日々精進中。

